Crawler: 网页表格爬虫; 多用于risk free rate的自动获取;
FolderSetUp: 自动创建文件夹树; 配合copy file macro 多用于Valuation当中每个月working folder的自动建立;
Relink: 自动批量换文件中的link;
仅作范本参考;
欢迎斧正;
Crawler+FolderSetUp+Relink.rar
J
jonathan-jiang 发布的帖子
-
一些有用的Macro发布在 Excel & VBA
-
以Excel VBA实现对网页中Table的爬虫 --- Part 2发布在 Excel & VBA
在上一篇帖子当中我们介绍了XMLHTTP对象及方法获取网页中Table对应的网页字符串. 那么如何从这些字符串中获取我们想要的数据呢?在python或者java中这些会有对应的包和函数可以实现. 而本篇将会介绍一种简单而基础的方法: 正则表达式 (Regex).
3.正则表达式 (Regex):
正则表达式是一种用于匹配字符串中字符模式的工具, 它可以用来搜索、编辑和处理文本.
正则表达式的作用非常强大,详细的总结可以参考CSDN大佬的帖子:VBA学习笔记六:正则表达式.
下面我会总结用到的一些对象和方法:
3.1 创建正则表达式对象:
3.1.1 前期绑定:
添加引用库:工具 > 引用 >勾选 ’Microsoft VBScript Regular Expressions 5.5‘
'直接声明reg对象就可以使用' Dim reg as New RegExp3.1.2 后期绑定 (推荐使用):
使用 CreateObject 方法来创建VBScript.RegExp对象,便可使用
代码'先声明再创建reg对象' Dim reg As Object Set reg = CreateObject("VBScript.RegExp")3.2 用到的属性及方法:
3.2.1 Pattern 属性
• 描述:定义要匹配的正则表达式模式
• 示例:匹配任意四个字母的单词
reg.Pattern = "\b\w{4}\b"
3.2.2 Global 属性
• 描述:设置是否全局搜索匹配。默认为 False,只匹配第一个
• 示例:全局匹配所有符合模式的字符串
reg.Global = True3.2.3 Execute 方法
• 描述:执行正则表达式匹配,查找所有符合匹配模式的子字符串,并返回一个匹配集合对象 (MatchCollection对象)
• 示例:查找匹配项,其中 string 是要搜索的字符串
Set matches = reg.Execute(string)3.3 匹配规则 这里我照抄CSDN文章:

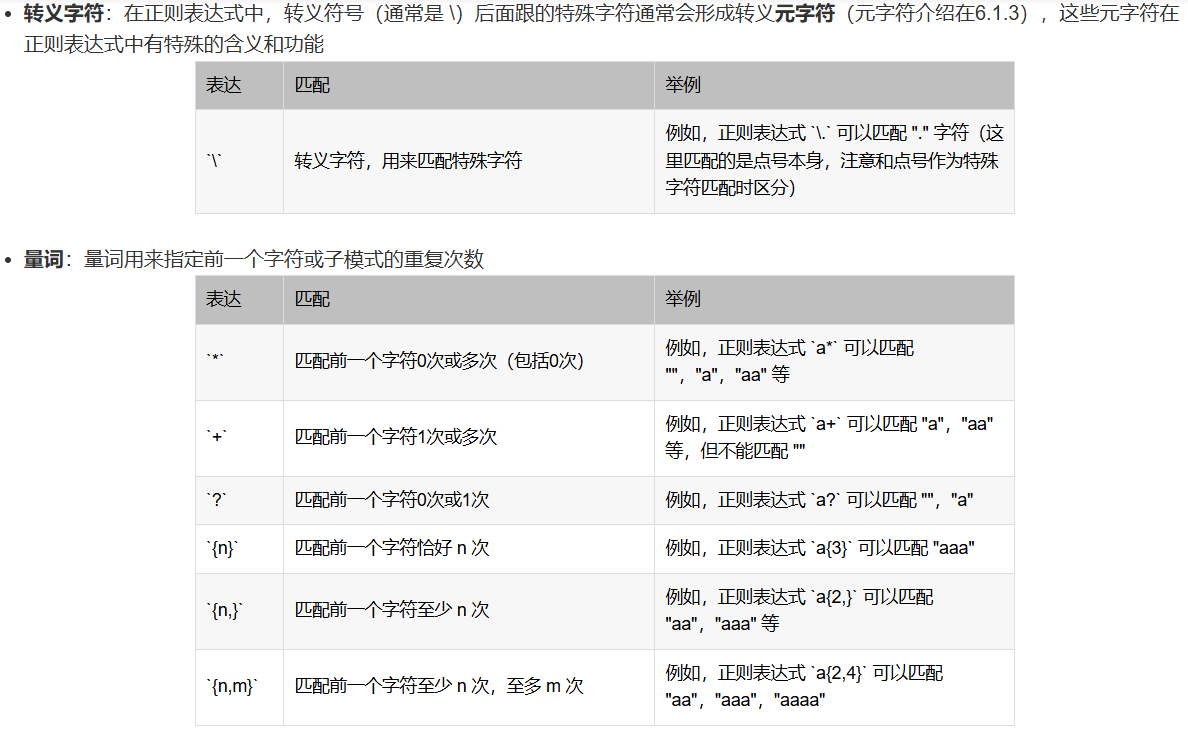
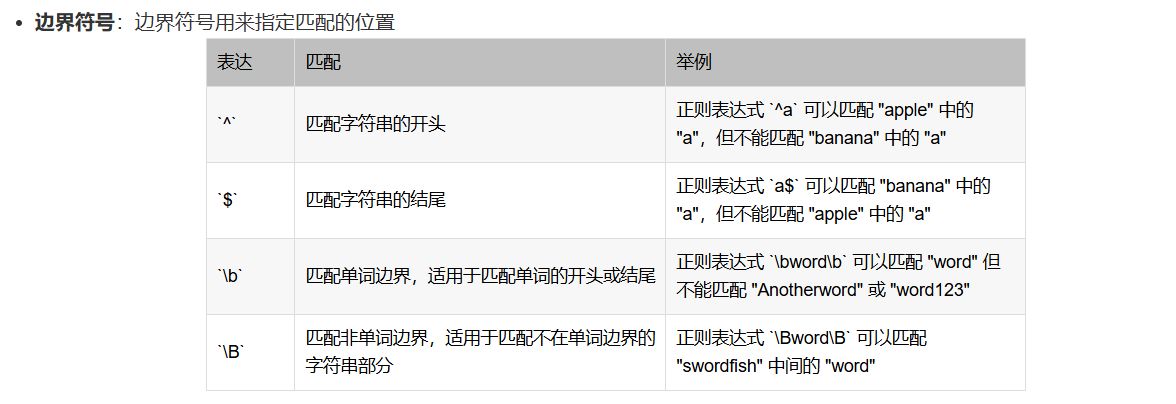

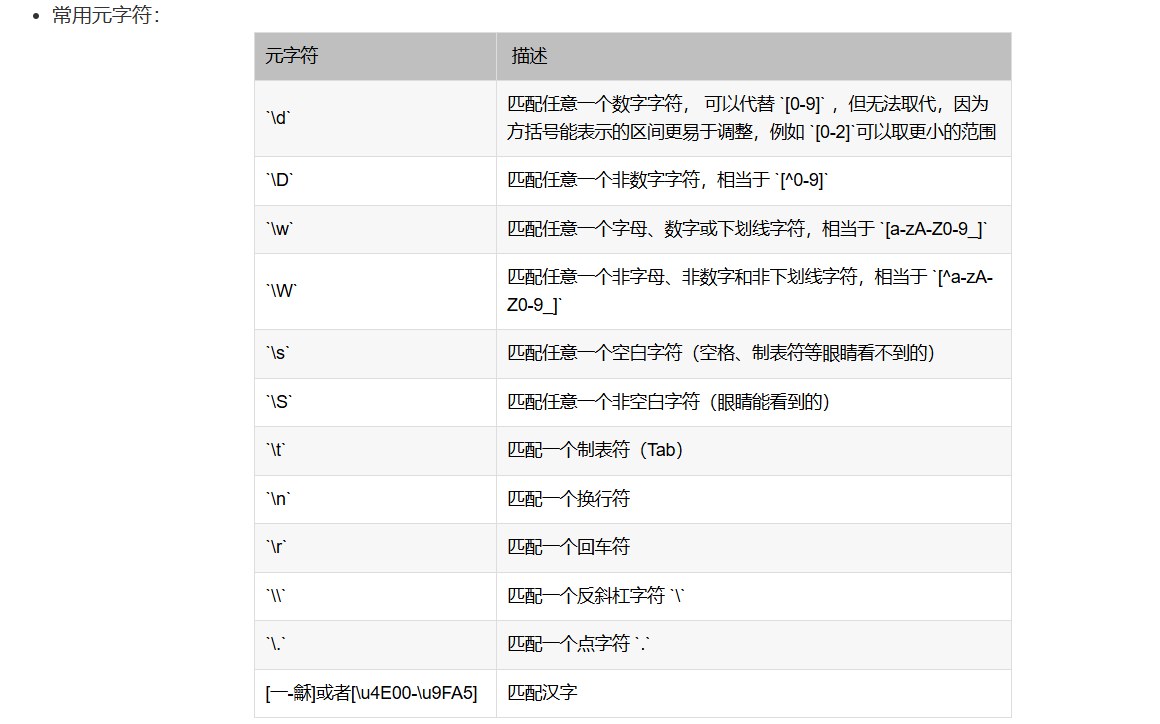



3.4 匹配结果的对象:
3.4.1 MatchCollection对象:
含义:是一个集合对象,包含了正则表达式在输入文本中找到的所有匹配项,每个匹配项都表示为一个 Match 对象.
用到的属性:
Item 属性
○ 功能:返回集合中第几个Match对象,从0开始计数
○ 用法:matches.Item(index)或matches(index)
○ 示例:输出第一个匹配到的对象
Set match = matches(0)
MsgBox "Found match: " & match.Value3.4.2 Match对象:
含义:表示正则表达式匹配中的一个匹配项,包含匹配的文本和其他相关信息
用到的属性:
SubMatches 属性
○ 功能:返回一个SubMatches集合(注意这里返回了集合,因而适用MatchCollection对象的所有方法),包含所有捕获的子匹配项,通过索引访问捕获组的内容(索引从0开始)可以获取匹配到的分组内容
○ 前提:在正则表达式模式中使用了括号来创建捕获组 (参考3.3.>>>)
○ 用法:match.SubMatches(n)*表示访问子匹配项第n+1个捕获组的内容,也就是表达式里面的第n+1个括号*这里的语法也可以写成
match.SubMatches.Item(n)来表达同样的意思。4.正则表达式应用实例:
4.1 代码及注释
Sub getrates(s As String) Dim reg As Object, m As Object, mchs As Object Dim i As Long, j As Long, p As String Set reg = CreateObject("vbscript.regexp")'后期绑定创建regex' '----regex' p = "<tr>\s*<td.*><time.*>([^<]*)</time>\s*</td>\s*<td.*>.*</td>\s*<td.*>.*</td>\s*<td.*>.*</td>\s*<td.*>.*</td>\s*<td.*>.*</td>\s*<td.*>.*</td>\s*<td.*>.*</td>\s*<td.*>.*</td>\s*<td.*>.*</td>\s*<td.*>.*</td>\s*<td.*>.*</td>\s*<td.*>([^<]*)</td>\s*<td.*>([^<]*)</td>\s*<td.*>([^<]*)</td>\s*<td.*>([^<]*)</td>\s*<td.*>([^<]*)</td>\s*<td.*>([^<]*)</td>\s*<td.*>([^<]*)</td>\s*<td.*>([^<]*)</td>\s*<td.*>([^<]*)</td>\s*<td.*>([^<]*)</td>\s*<td.*>([^<]*)</td>\s*<td.*>([^<]*)</td>\s*<td.*>([^<]*)</td>\s*<td.*>([^<]*)</td>\s*</tr>" reg.pattern = p'3.2.1 pattern属性' reg.Global = True'3.2.2 global属性' Set mchs = reg.Execute(s)'3.2.3 execute方法' i = 6 For Each m In mchs'3.4.1 MatchCollection对象' For j = 0 To m.submatches.Count - 1 Cells(i, j + 1) = m.submatches.Item(j) '利用3.4.2match对象的submatches属性去将捕获字符输出到单元格中' Next j i = i + 1 Next m End Sub4.2 正则表达式
p的写法:这里我复制出来整个Table的字符串, 以第一行(
<tr>...</tr>为一行的字符串)为例, 用黄色标出来我想要的字符.
参照3.3匹配规则中的捕获组方法, 将需要输出的字符以
()包含进去,根据网页字符串的语法<tr>.*</tr>和<td>.*</td>做一些识别与中间内容的捕获, 作者就得到了如下的正则表达式.
5.总结:
作者所使用的方法基本可以分为两步:
第一步, 利用XMLHTTP对象先从网页中返回字符串;
第二步, 利用正则表达式的匹配及捕获funtion从字符串中返回需要的字符6.杂谈:
本帖是作者应管理员珂珂之邀写的第一篇技术分享帖子, 谢邀~
但作者对本论坛的流量表示怀疑, 因为截止到作者写part 2时, part 1帖仅有两个浏览量, 其中一个还是作者本人贡献QAQ.
在此呼吁珂珂阿姨将论坛内容在公众号中做实时更新, 并祝愿珂珂阿姨做大做强, 再创辉煌~ 此致, 敬礼^.^-!
-
以Excel VBA实现对网页中Table的爬虫 --- Part 1发布在 Excel & VBA
1.需求与基本概念:
1.1 需求:
在我们平时的工作当中,往往会需要去获取一些诸如国债收益率的信息,而这些信息是写在官网的table上面的,需要我们手动去复制粘贴出来,非常浪费时间。因此就有利用爬虫(crawler)去自动获取的需求。1.2 爬虫的概念:

写爬虫的方法在不同的语言当中不尽相同,有用python的,也有用java的,而就工作实用性而言,VBA相对容易获得,毕竟不需要再去安装python的语言包。本文仅介绍基于EXCEL VBA对table的爬虫方法。
2.基本方法介绍:
2.1 XMLHTTP对象:
XMLHTTP对象在VBA中用于在后台与服务器(Server)交换数据。XMLHTTP对象能够:
在不重新加载页面的情况下更新网页
在页面已加载后从服务器请求数据
在页面已加载后从服务器接收数据
在后台向服务器发送数据2.2 XMLHTTP对象及方法介绍:
i. 定义XMLHTTP对象:Set xml = CreateObject("microsoft.xmlhttp") '调用网络访问组件,相当于双击打开浏览器ii. Open方法:
xml.Open "get", strURL, False 'strURL代表网址字符串,这一步相当于打开网页语法介绍:
open(bstrMethod, bstrUrl, varAsync, bstrUser, bstrPassword)
bstrMethod: 数据传送方式,即GET或POST。用POST方式发送数据,可以大到4MB,也可以换为GET,只能256KB。
bstrUrl: 服务网页的URL。
varAsync: 是否同步执行。缺省为True,即同步执行,但只能在DOM中实施同步执行。用中一般将其置为False,即异步执行。
bstrUser: 用户名,可省略。
bstrPassword:用户口令,可省略。iii. Send方法:
xml.send'提交请求,类似于回车'send(varBody)
语法介绍:
varBody:指令集。可以是XML格式数据,也可以是字符串,流,或者一个无符号整数数组。也可以省略,让指令通过Open方法的URL参数代入。发送数据的方式分为同步和异步两种。在异步方式下,数据包一旦发送完毕,就结束Send进程,客户机执行的操作;而在同步方式下,客户机要等到服务器返回确认消息后才结束Send进程。iv. responsetext属性:
s = xml.responsetext'responsetext得到网页字符串'xml.responseText
string型 结果返回为字符串。这一步就相当于返回了网页字符串,这个过程也可以手动显示出来,这个在后面写正则表达式(regex)的时候将会非常有用:
首先打开网页,输入对应的网址
以美债国库券Yield Curve为例:https://home.treasury.gov/resource-center/data-chart-center/interest-rates/TextView?type=daily_treasury_yield_curve&field_tdr_date_value=2025
然后按F12,这样就可以显示出来网页的code。
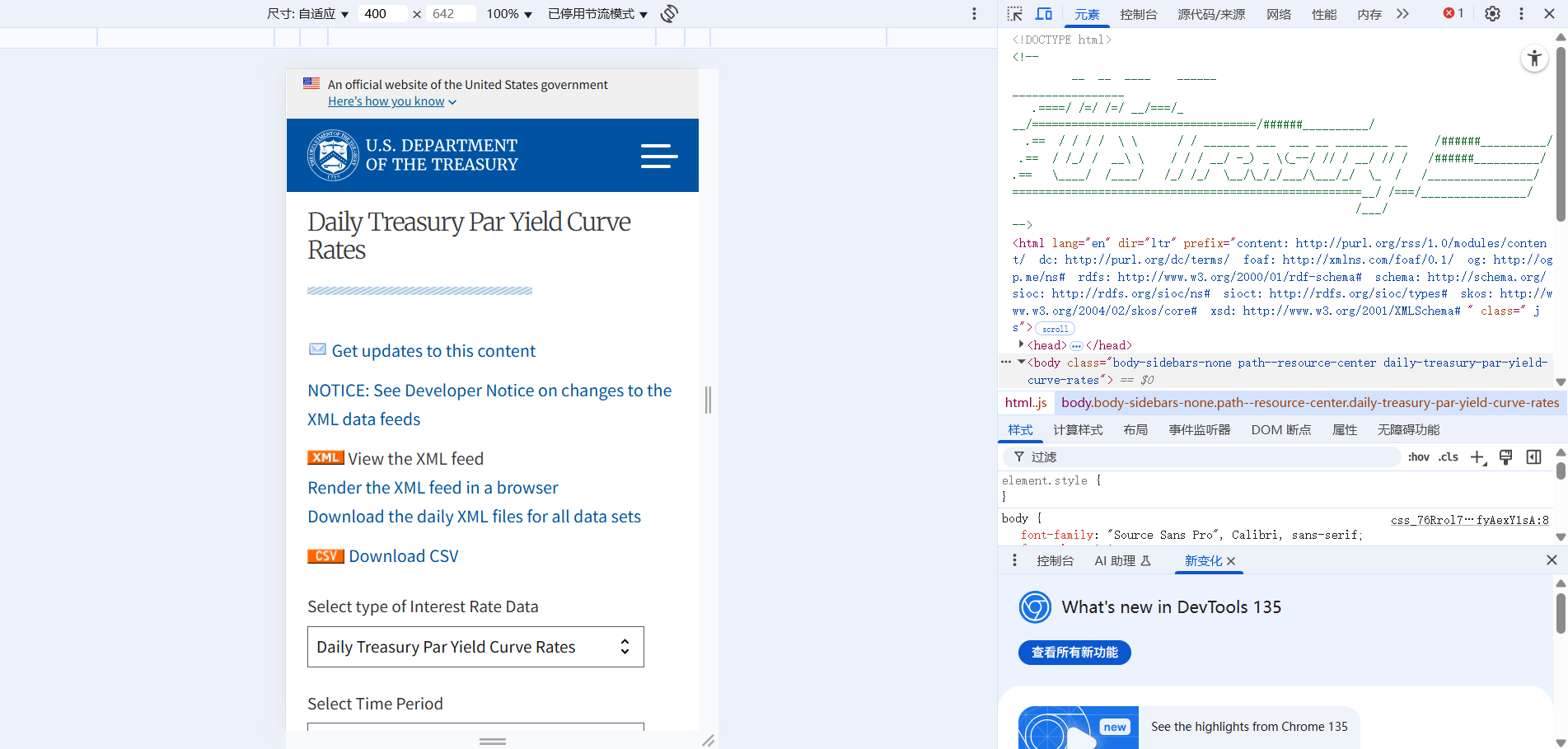
然后我们可以找得到这个Table对应的code:<table>***</table>这一段,我们可以把这个copy出来方便我们之后写正则表达式。
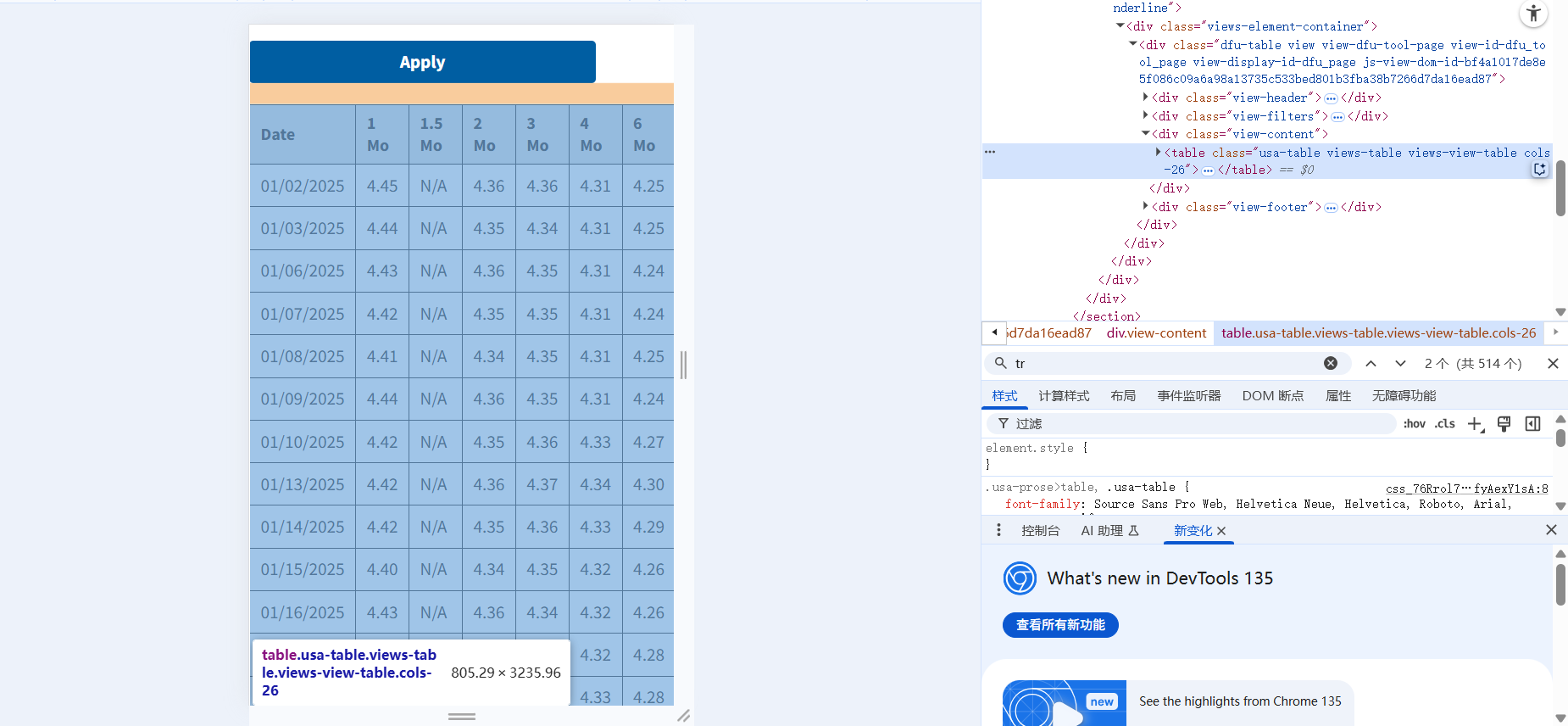
根据网页字符串的写法,<tr>...<tr>就代表一行中间的内容,有多少行就会有多少个<tr>...<tr>。这个我们之后介绍正则表达式的时候再去详细介绍。
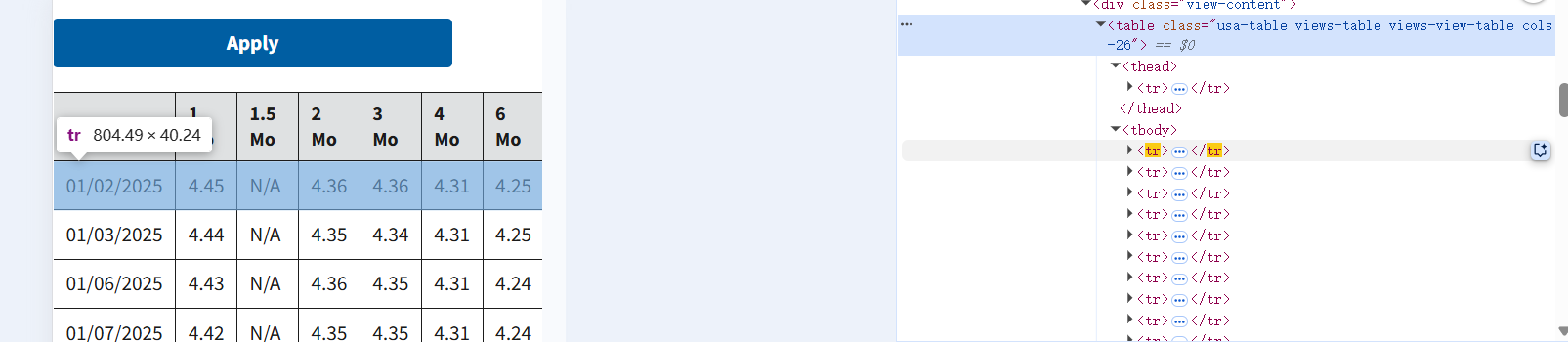
所以到现在为止,我们介绍了如何利用XLMHTTP对象访问网页并且返回网页字符串。那么如何从这些字符串当中提取想要的信息呢?请关注博主的第二篇帖子。