Modelling claim frequency R 問題
-
library(ggplot2) library(dplyr) library(class) library(MASS) library(caret) library(devtools) library(countreg) library(forcats) library(AER) library(pscl) install.packages("countreg", repos="http://R-Forge.R-project.org") #Attaching data for modeling data(dataCar) data1 <- dataCar #Data Cleaning & Pre-processing data2 <- unique(data1) data3 <- data2[data2\$veh_value > quantile(data2\$veh_value, 0.0001),] data4 <- data3[data3\$veh_value < quantile(data3\$veh_value, 0.999), ] #Regrouping vehicle categories top9 <- c('SEDAN','HBACK','STNWG','UTE','TRUCK','HDTOP','COUPE','PANVN','MIBUS') data4\$veh_body <- fct_other(data4\$veh_body, keep = top9, other_level = 'other') #Converting catagorical variables into factors names <- c('veh_body' ,'veh_age','gender','area','agecat') data4[,names] <- lapply(data4[,names] , factor) str(data4) ##data partition - original data data <- data4 data_partition <- createDataPartition(data\$numclaims, times = 1,p = 0.8,list = FALSE) str(data_partition) training <- data[data_partition,] testing <- data[-data_partition,] #Re-sampling sample1 <- subset(data4, numclaims!=0) sample2 <- data4[ sample( which(data4\$numclaims==0), round(0.9*length(which(data4\$numclaims==0)))), ] sample3 <- data4[ sample( which(data4\$numclaims==0), round(0.1*length(which(data4\$numclaims==0)))), ] y <- rnbinom(n = 6323, mu = 1, size = 3) # n value should be equal to sample 3 sample3\$numclaims <- y df_sample <- rbind(sample1,sample2,sample3)我在學習怎麼用R 去模擬claim frequency 在網上看見這個例子 開始在最後的
y <- rnbinom(n = 6323, mu = 1, size = 3) # n value should be equal to sample 3 sample3\$numclaims <- y df_sample <- rbind(sample1,sample2,sample3)我在學習怎麼用R 去模擬claim frequency 在網上看見這個例子 開始在
y <- rnbinom(n = 6323, mu = 1, size = 3) # n value should be equal to sample 3 sample3\$numclaims <- y df_sample <- rbind(sample1,sample2,sample3)
我在學習怎麼用R 去模擬claim frequency 在網上看見這個例子 開始在最後的random negative binomial simulation 裡面 mu=1 和 size=3 是怎麼得出的呢?
還有df_sample 是什麼意思?
有大神可以指教一下? 抱歉 新手用R 嘗試自己理解
-
Hi Sunseeker,
很荣幸解答你的问题。我想这不仅仅是一个R相关的问题,更是一个建模思路上的问题
我查阅了一下万能的互联网,发现这个Model Claim Frequency来源于这个网站
里面着重讲到了一个概念,叫做"over-dispersion",意思就是实际上某变量的波动性比拟合的分布的波动性要高。这是保险理赔数据常常会出现的一个问题。
不过幸运的是,由于原本数据集的特性,over-dispersion没有造成很大影响,Poission分布拟合的效果还是不错的:
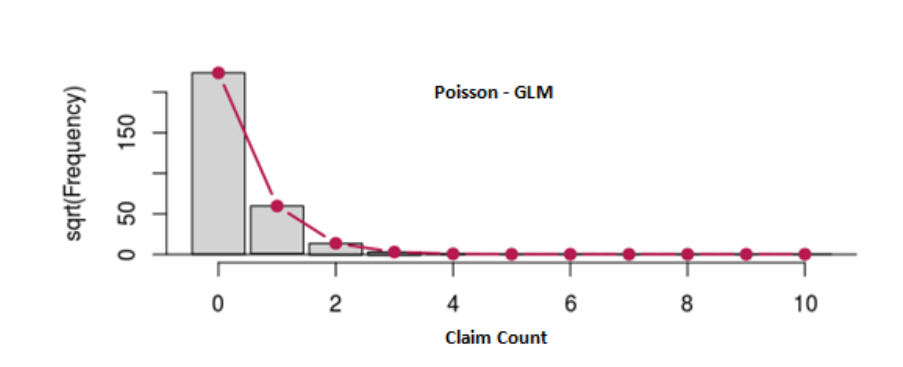
为了探究over-dispersion"会带来的影响,作者拿出了10%的数据,把这些数据里面的理赔量手动调整成负二项分布。这里面的sample 3就是原本数据里面拿出的10%的数据。df_sample是把这10%的数据和别的数据放回到了一起。mu和size的值不需要太关注,因为这就是一个数据模拟而已。这整个过程叫做Resample。
sample3 <- data4[ sample( which(data4\$numclaims==0), round(0.1*length(which(data4\$numclaims==0)))), ] y <- rnbinom(n = 6323, mu = 1, size = 3) # n value should be equal to sample 3 sample3\$numclaims <- y df_sample <- rbind(sample1,sample2,sample3)最后,用resample后的数据来看,Negative Binominal的拟合效果果然更好。
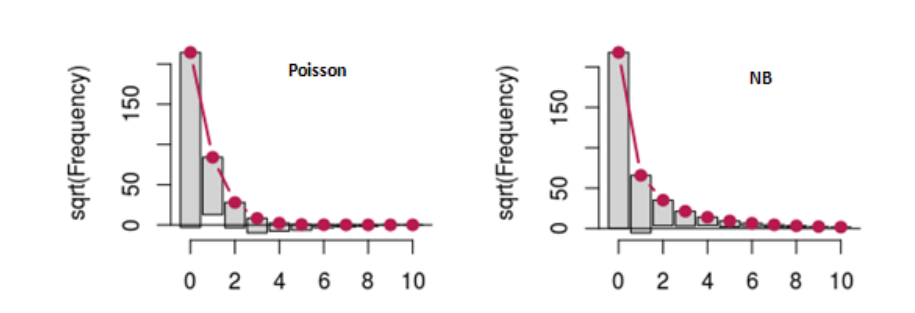
希望这个解答了你的问题。欢迎讨论~