从动态网页中爬Request的经验
-
最近爬了两个动态网站。很有意思,和大家分享一下爬虫的过程。
爬虫像是一个解谜的游戏,通过读代码和网页监控Request记录可以一步步推断如何把想要的信息爬取出来。
-
由于各种原因,不方便透露是哪两个网站。但是可以和大家分享一下一些心得。
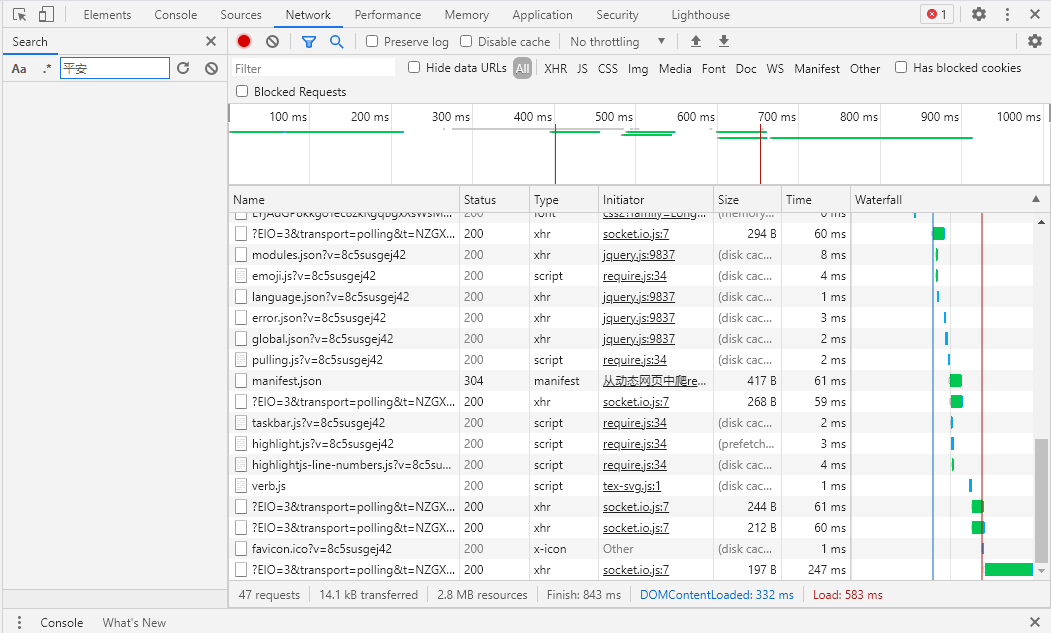
第一个网站中,关键的突破点是通过浏览器的网络监控(Chrome点击F12,并选择Network如下图),点击Ctrl+F,输入想要爬取信息的关键词(我这里是“平安”),成功检索到了网站提取信息的Url。
第二个网站就更有意思了,我发现这个网页是首先把所有的数据提取出来后,分页完全是前端进行的。而数据变量还存储在浏览器中。我找到数据变量"List"后,在浏览器console运行了如下的js代码,这是一个用于储存浏览器中变量的函数。(function(console){ console.save = function(data, filename){ if(!data) { console.error('Console.save: No data') return; } if(!filename) filename = 'console.json' if(typeof data === "object"){ data = JSON.stringify(data, undefined, 4) } var blob = new Blob([data], {type: 'text/json'}), e = document.createEvent('MouseEvents'), a = document.createElement('a') a.download = filename a.href = window.URL.createObjectURL(blob) a.dataset.downloadurl = ['text/json', a.download, a.href].join(':') e.initMouseEvent('click', true, false, window, 0, 0, 0, 0, 0, false, false, false, false, 0, null) a.dispatchEvent(e) } })(console)然后运行
console.save(List, "List.txt")变量List就存储到List.txt这个文档中了。基本上整个过程是无代码爬虫。